

This is the second installment in a series of blogs that detail how and why we built our Attribution Engine. Missed the first blog on our product principles? Catch up here.
At Pex, we are committed to investing in research and development and building state-of-the-art content identification technology into our product. I find it incredibly exciting to be part of a company that not only develops the fastest and most accurate content identification in the market, but is also dedicated to continuously improving our algorithms so that we remain leading-edge. Our team of individuals with backgrounds in industry and academia is tuned into the latest developments in the research community, the biggest challenges faced by copyright owners, and the result is a groundbreaking product that we are always making even better.
We use our technology to identify uses of copyright online, so that the proper creators or companies can receive attribution and compensation for the use of their works. We believe in attribution for all, and we can’t deliver on that vision without technology capable of handling the complexities of digital content.
To better understand our technology and the kind of problems we solve through our Attribution Engine, we need to start at the beginning.
What is content identification?
Content identification, often called automated content recognition or ACR, is the process of scanning and matching pieces of content (which can include audio, video, images, text, or other variations) based on a reference file. Content identification isn’t a new technology – you may be familiar with it from the popular music app Shazam – but as new types of content have emerged, the amount of content on the internet has exploded. And as uploaders have learned to skate around common identification practices, it has become more and more difficult to accurately and quickly identify content online.

What makes content identification so challenging, and also so fun to work on?
With simple identifications, it’s quite straightforward to compare two identical pieces of content and determine if they are the same. As humans, we can just listen to two songs and determine if they are the same or not. But what if we want to answer more complex questions, such as:
- Does this piece of audio match any known copyrighted work ever created, even if just for a few seconds?
- Is this a distorted version of our resource file, where the volume has been changed, tempo has changed, or background noise has been added?
When trying to answer these complex questions, it becomes infeasible to compare content without technology. And we have to make sure that when we compare, we aren’t fooled by any modifications to the original, which uploaders often use to avoid having their content discovered. Then we need to think about scale: billions of pieces of content are uploaded daily. How can we identify content accurately, granularly, at scale, and invariant to distortions? These are the challenges that make it so fun to work at Pex and to work on our identification technology.
Pex’s technology
At Pex, we use digital fingerprinting to enable content identification. A fingerprint is a compact representation of a piece of content that allows us to robustly and efficiently match against other pieces of that same content type. Our fingerprinting tech powers our identification capabilities, which are the base of our products, including our Attribution Engine.
Attribution Engine relies on fingerprinting to process and identify content in mass and at the scale of the Internet. Our advancements in this technology allow us to identify content in real time, as it’s uploaded to content-sharing platforms, so we can fundamentally change the way content is attributed and published. Identifying, attributing, and licensing the use of copyrighted content before it’s shared online balances the creator economy by ensuring rights are respected, copyright use is compensated, and content is still able to flow freely.
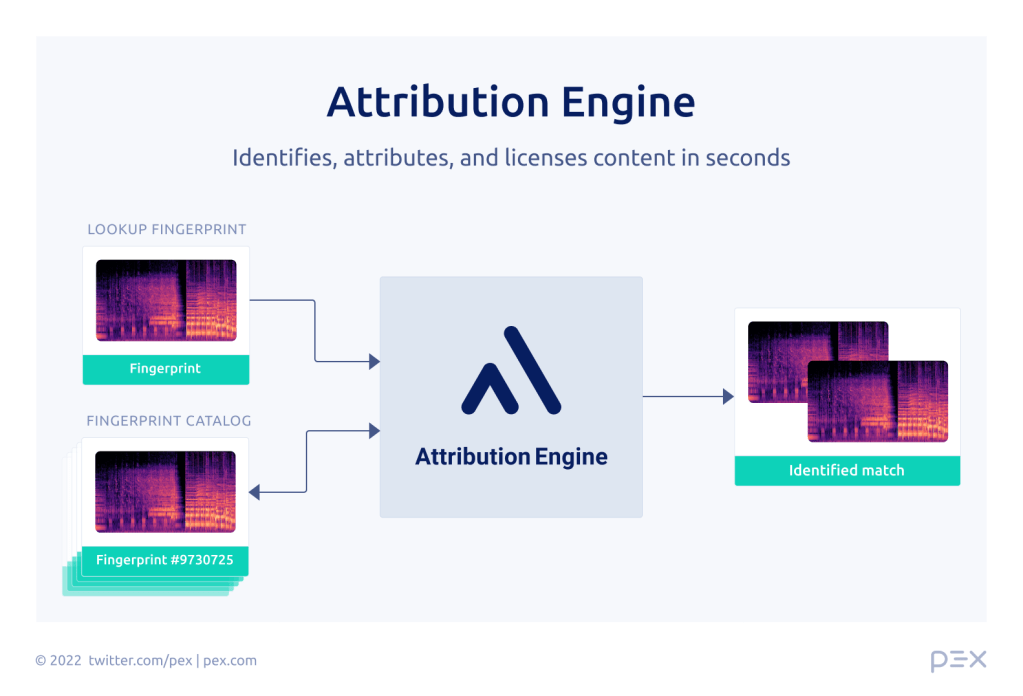
The need for this balance in the creator economy is why we continuously and obsessively improve our approach to fingerprinting and matching content. We are always iterating in order for our algorithms to:
- Identify content faster and at enormous scale
- Find more true positive matches to correctly identify as many matches as possible
- Find fewer false positive matches, targeting zero because that is critical for copyright
- Process more content types in addition to audio, video, and melody which we currently support
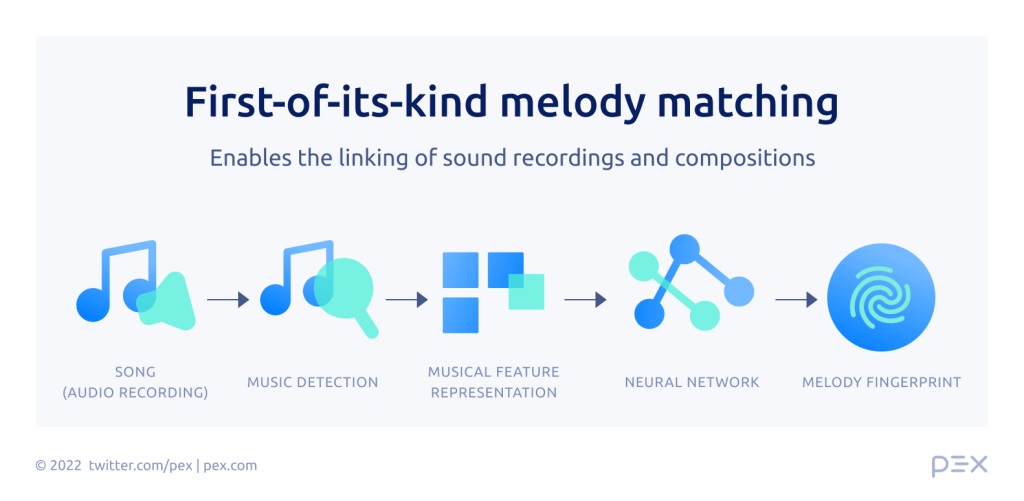
First-of-its-kind melody matching
We also prioritize research and development to solve major industry problems. We are incredibly excited about our melody matching system, which is aimed to address the challenge of attribution for music composition rightsholders and one of the major challenges in building a global rights database. Music composition rightsholders (songwriters and their publishing companies) receive lower royalty rates than those of recording artists or record labels. On top of this, they struggle to find uses of their copyright and claim them for additional revenue, and this is because of shortcomings in audio identification.
Audio matching for sound recordings is the bread and butter of the content identification world, but matching against only sound recordings leaves gaps in attribution. For example, composition rightsholders have no way to be attributed or compensated when someone uploads a cover song of their work, because the sound recordings are different.
To help solve this problem, we developed melody matching, which allows us to match two pieces of audio when they represent the same underlying composition, even when the sound recordings differ. Our melody matching can also help us link sound recordings with compositions in our database, which has been a sticking point for others who have attempted to create a global rights database like Pex’s Registry. Our system leverages our deep knowledge and experience with audio identification, together with neural networks and concepts from the forefront of the machine learning research community, to identify and match using the melody of a song.
We have developed trail-blazing algorithms for melody matching that will bring new revenue and proper attribution to an underserved part of the music industry. These are the research problems we love to work on and prioritize at Pex.
The building blocks of Attribution Engine
Our identification technology is just one part of our Attribution Engine. While it is the foundation for all that we do, there are many other key modules that combine to create this all-in-one copyright solution for the creator economy. Stay tuned as we dive into more areas of product development and how we built this game-changing solution.
Want to work with us to solve complex problems? Check out open roles.









